阿里云优惠活动,点击链接进行购买: 一年仅需96.9元即可以购买服务器~
腾讯云优惠活动, 点击链接进行购买一年仅需99元
腾讯云限时开团活动, 点击链接进行购买一年仅需95元
平常在写业务的时候常常会用的到的是 GET, POST请求去请求接口,GET 相关的接口会比较容易基本不会出错,而对于 POST中常用的 表单提交,JSON提交也比较容易,但是对于文件上传呢?大家可能对这个步骤会比较害怕,因为可能大家对它并不是怎么熟悉,而浏览器Network对它也没有详细的进行记录,因此它成为了我们心中的一根刺,我们老是无法确定,关于文件上传到底是我写的有问题呢?还是后端有问题,当然,我们一般都比较谦虚, 总是会在自己身上找原因,可是往往实事呢?可能就出在后端身上,可能是他接受写的有问题,导致你换了各种请求库去尝试,axios,request,fetch 等等。那么我们如何避免这种情况呢?我们自身要对这一块够熟悉,才能不以猜的方式去写代码。如果你觉得我以上说的你有同感,那么你阅读完这篇文章你将收获自信,你将不会质疑自己,不会以猜的方式去写代码。
本文比较长可能需要花点时间去看,需要有耐心,我采用自顶向下的方式,所有示例会先展现出你熟悉的方式,再一层层往下, 先从请求端是怎么发送文件的,再到接收端是怎么解析文件的。以下是讲解的大纲,我们先从浏览器端上传文件,再到服务端上传文件,然后我们再来解析文件是如何被解析的。
multipart/form-data 最初由 《RFC 1867: Form-based File Upload in HTML》 (opens new window)文档提出。
Since file-upload is a feature that will benefit many applications, this proposes an extension to HTML to allow information providers to express file upload requests uniformly, and a MIME compatible representation for file upload responses.
由于文件上传功能将使许多应用程序受益,因此建议对 HTML 进行扩展,以允许信息提供者统一表达文件上传请求,并提供文件上传响应的 MIME 兼容表示。
总结就是原先的规范不满足啦,我要扩充规范了。
The encoding type application/x-www-form-urlencoded is inefficient for sending large quantities of binary data or text containing non-ASCII characters. Thus, a new media type,multipart/form-data, is proposed as a way of efficiently sending the values associated with a filled-out form from client to server.
1867 文档中也写了为什么要新增一个类型,而不使用旧有的application/x-www-form-urlencoded:因为此类型不适合用于传输大型二进制数据或者包含非 ASCII 字符的数据。平常我们使用这个类型都是把表单数据使用 url 编码后传送给后端,二进制文件当然没办法一起编码进去了。所以multipart/form-data就诞生了,专门用于有效的传输文件。
也许你有疑问?那可以用 application/json吗?
其实我认为,无论你用什么都可以传,只不过会要综合考虑一些因素的话,multipart/form-data更好。例如我们知道了文件是以二进制的形式存在,application/json 是以文本形式进行传输,那么某种意义上我们确实可以将文件转成例如文本形式的 Base64 形式。但是呢,你转成这样的形式,后端也需要按照你这样传输的形式,做特殊的解析。并且文本在传输过程中是相比二进制效率低的,那么对于我们动辄几十 M 几百 M 的文件来说是速度是更慢的。
以上为什么文件传输要用multipart/form-data 我还可以举个例子,例如你在中国,你想要去美洲,我们的multipart/form-data相当于是选择飞机,而application/json相当于高铁,但是呢?中国和美洲之间没有高铁啊,你执意要坐高铁去,你可以花昂贵的代价(后端额外解析你的文本)造高铁去美洲,但是你有更加廉价的方式坐飞机(使用multipart/form-data)去美洲(去传输文件)。你图啥?(如果你有钱有时间,抱歉,打扰了,老子给你道歉)
摘自 《RFC 1867: Form-based File Upload in HTML》 (opens new window) 6.Example
Content-type: multipart/form-data, boundary=AaB03x
--AaB03x
content-disposition: form-data; name="field1"
Joe Blow
--AaB03x
content-disposition: form-data; name="pics"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
可以简单解释一些,首先是请求类型,然后是一个 boundary (分割符),这个东西是干啥的呢?其实看名字就知道,分隔符,当时分割作用,因为可能有多文件多字段,每个字段文件之间,我们无法准确地去判断这个文件哪里到哪里为截止状态。因此需要有分隔符来进行划分。然后再接下来就是声明内容的描述是 form-data 类型,字段名字是啥,如果是文件的话,得知道文件名是啥,还有这个文件的类型是啥,这个也很好理解,我上传一个文件,我总得告诉后端,我传的是个啥,是图片?还是一个 txt 文本?这些信息肯定得告诉人家,别人才好去进行判断,后面我们也会讲到如果这些没有声明的时候,会发生什么?
好了讲完了这些前置知识,我们接下来要进入我们的主题了。面对 File, formData,Blob,Base64,ArrayBuffer,到底怎么做?还有文件上传不仅仅是前端的事。服务端也可以文件上传(例如我们利用某云,把静态资源上传到 OSS 对象存储)。服务端和客户端也有各种类型,Buffer,Stream,Base64....头秃,怎么搞?不急,就是因为上传文件不单单是前端的事,所以我将以下上传文件的一方称为请求端,接受文件一方称为接收方。我会以请求端各种上传方式,接收端是怎么解析我们的文件以及我们最终的杀手锏调试工具-wireshark 来进行讲解。
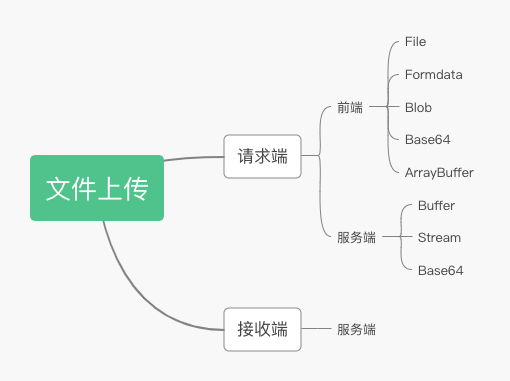
首先我们先写下最简单的一个表单提交方式。
<form action="http://localhost:7787/files" method="POST">
<input name="file" type="file" id="file" />
<input type="submit" value="提交" />
</form>
我们选择文件后上传,发现后端返回了文件不存在。

不用着急,熟悉的同学可能立马知道是啥原因了。嘘,知道了也听我慢慢叨叨。
我们打开控制台,由于表单提交会进行网页跳转,因此我们勾选preserve log 来进行日志追踪。
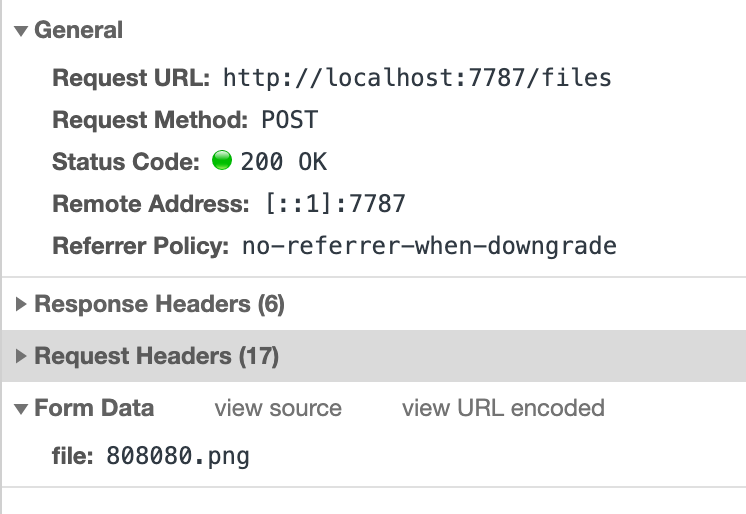
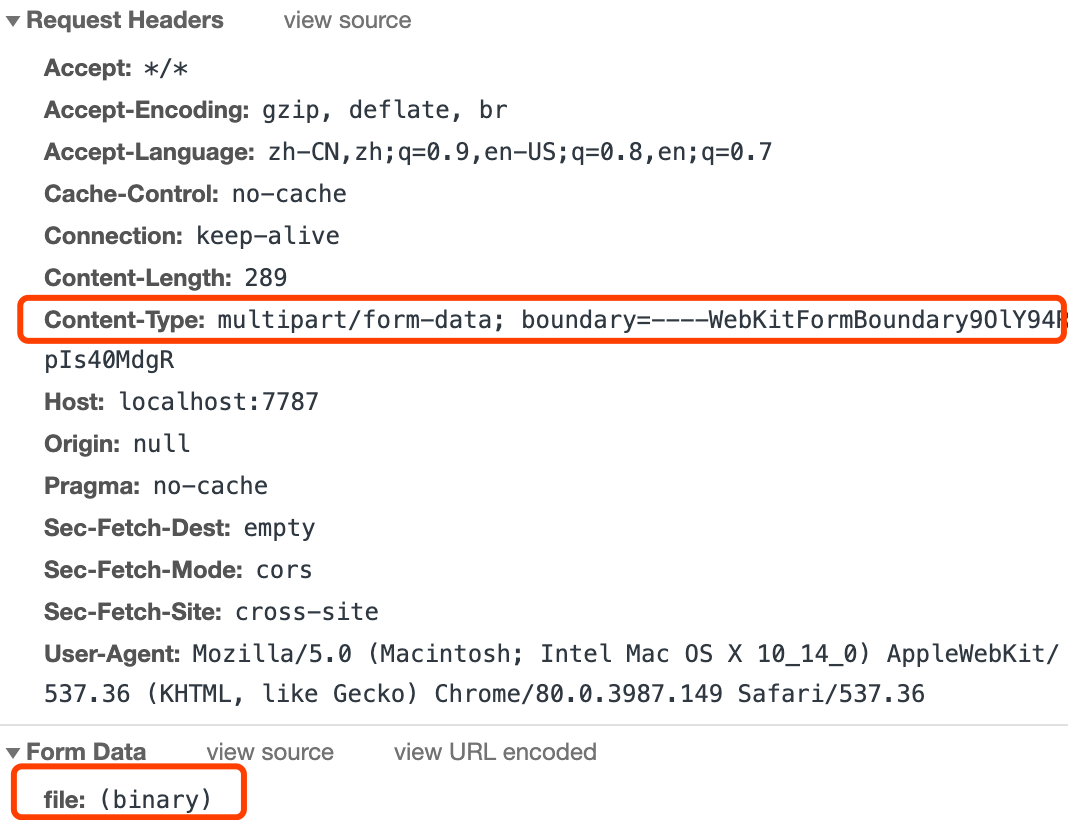
我们可以发现其实 FormData 中 file 字段显示的是文件名,并没有将真正的内容进行传输。再看请求头。
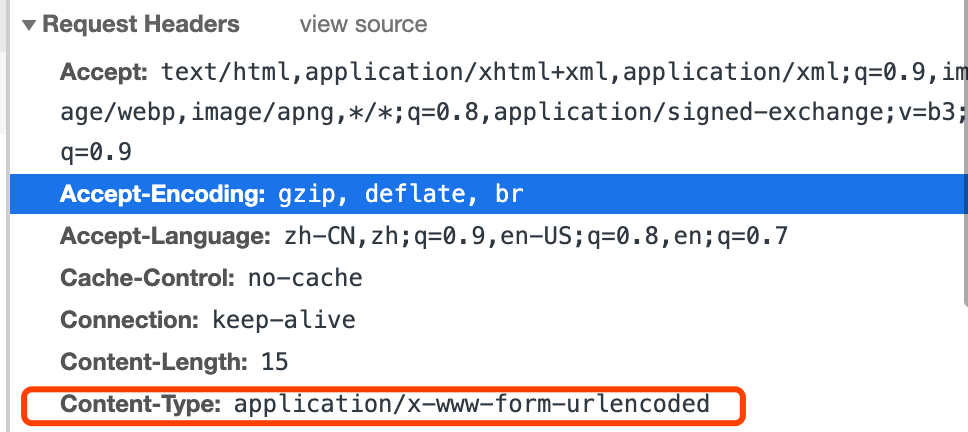
发现是请求头和预期不符,也印证了 application/x-www-form-urlencoded 无法进行文件上传。
我们加上请求头,再次请求。
<form
action="http://localhost:7787/files"
enctype="multipart/form-data"
method="POST"
>
<input name="file" type="file" id="file" />
<input type="submit" value="提交" />
</form>

发现文件上传成功,简单的表单上传就是像以上一样简单。但是你得熟记文件上传的格式以及类型。
formData 的方式我随便写了以下几种方式。
<input type="file" id="file" />
<button id="submit">上传</button>
<script src="https://cdn.bootcss.com/axios/0.19.2/axios.min.js"></script>
<script>
submit.onclick = () => {
const file = document.getElementById("file").files[0];
var form = new FormData();
form.append("file", file);
// type 1
axios.post("http://localhost:7787/files", form).then((res) => {
console.log(res.data);
});
// type 2
fetch("http://localhost:7787/files", {
method: "POST",
body: form,
})
.then((res) => res.json())
.tehn((res) => {
console.log(res);
});
// type3
var xhr = new XMLHttpRequest();
xhr.open("POST", "http://localhost:7787/files", true);
xhr.onload = function() {
console.log(xhr.responseText);
};
xhr.send(form);
};
</script>
以上几种方式都是可以的。但是呢,请求库这么多,我随便在 npm 上一搜就有几百个请求相关的库。
因此,掌握请求库的写法并不是我们的目标,目标只有一个还是掌握文件上传的请求头和请求内容。
Blob 对象表示一个不可变、原始数据的类文件对象。Blob 表示的不一定是 JavaScript 原生格式的数据。File (opens new window) 接口基于Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。
因此如果我们遇到 Blob 方式的文件上方式不用害怕,可以用以下两种方式:
1.直接使用 blob 上传
const json = { hello: "world" };
const blob = new Blob([JSON.stringify(json, null, 2)], {
type: "application/json",
});
const form = new FormData();
form.append("file", blob, "1.json");
axios.post("http://localhost:7787/files", form);
2.使用 File 对象,再进行一次包装(File 兼容性可能会差一些 https://caniuse.com/#search=File)
const json = { hello: "world" };
const blob = new Blob([JSON.stringify(json, null, 2)], {
type: "application/json",
});
const file = new File([blob], "1.json");
form.append("file", file);
axios.post("http://localhost:7787/files", form);
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。
虽然它用的比较少,但是他是最贴近文件流的方式了。
在浏览器中,他每个字节以十进制的方式存在。我提前准备了一张图片。
const bufferArrary = [
137,
80,
78,
71,
13,
10,
26,
10,
0,
0,
0,
13,
73,
72,
68,
82,
0,
0,
0,
1,
0,
0,
0,
1,
1,
3,
0,
0,
0,
37,
219,
86,
202,
0,
0,
0,
6,
80,
76,
84,
69,
0,
0,
255,
128,
128,
128,
76,
108,
191,
213,
0,
0,
0,
9,
112,
72,
89,
115,
0,
0,
14,
196,
0,
0,
14,
196,
1,
149,
43,
14,
27,
0,
0,
0,
10,
73,
68,
65,
84,
8,
153,
99,
96,
0,
0,
0,
2,
0,
1,
244,
113,
100,
166,
0,
0,
0,
0,
73,
69,
78,
68,
174,
66,
96,
130,
];
const array = Uint8Array.from(bufferArrary);
const blob = new Blob([array], { type: "image/png" });
const form = new FormData();
form.append("file", blob, "1.png");
axios.post("http://localhost:7787/files", form);
这里需要注意的是 new Blob([typedArray.buffer], {type: 'xxx'}),第一个参数是由一个数组包裹。里面是 typedArray 类型的 buffer。
const base64 =
"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABAQMAAAAl21bKAAAABlBMVEUAAP+AgIBMbL/VAAAACXBIWXMAAA7EAAAOxAGVKw4bAAAACklEQVQImWNgAAAAAgAB9HFkpgAAAABJRU5ErkJggg==";
const byteCharacters = atob(base64);
const byteNumbers = new Array(byteCharacters.length);
for (let i = 0; i < byteCharacters.length; i++) {
byteNumbers[i] = byteCharacters.charCodeAt(i);
}
const array = Uint8Array.from(byteNumbers);
const blob = new Blob([array], { type: "image/png" });
const form = new FormData();
form.append("file", blob, "1.png");
axios.post("http://localhost:7787/files", form);
关于 base64 的转化和原理可以看这两篇 base64 原理 (opens new window) 和
原来浏览器原生支持 JS Base64 编码解码 (opens new window)
对于浏览器端的文件上传,可以归结出一个套路,所有东西核心思路就是构造出 File 对象。然后观察请求 Content-Type,再看请求体是否有信息缺失。而以上这些二进制数据类型的转化可以看以下表。
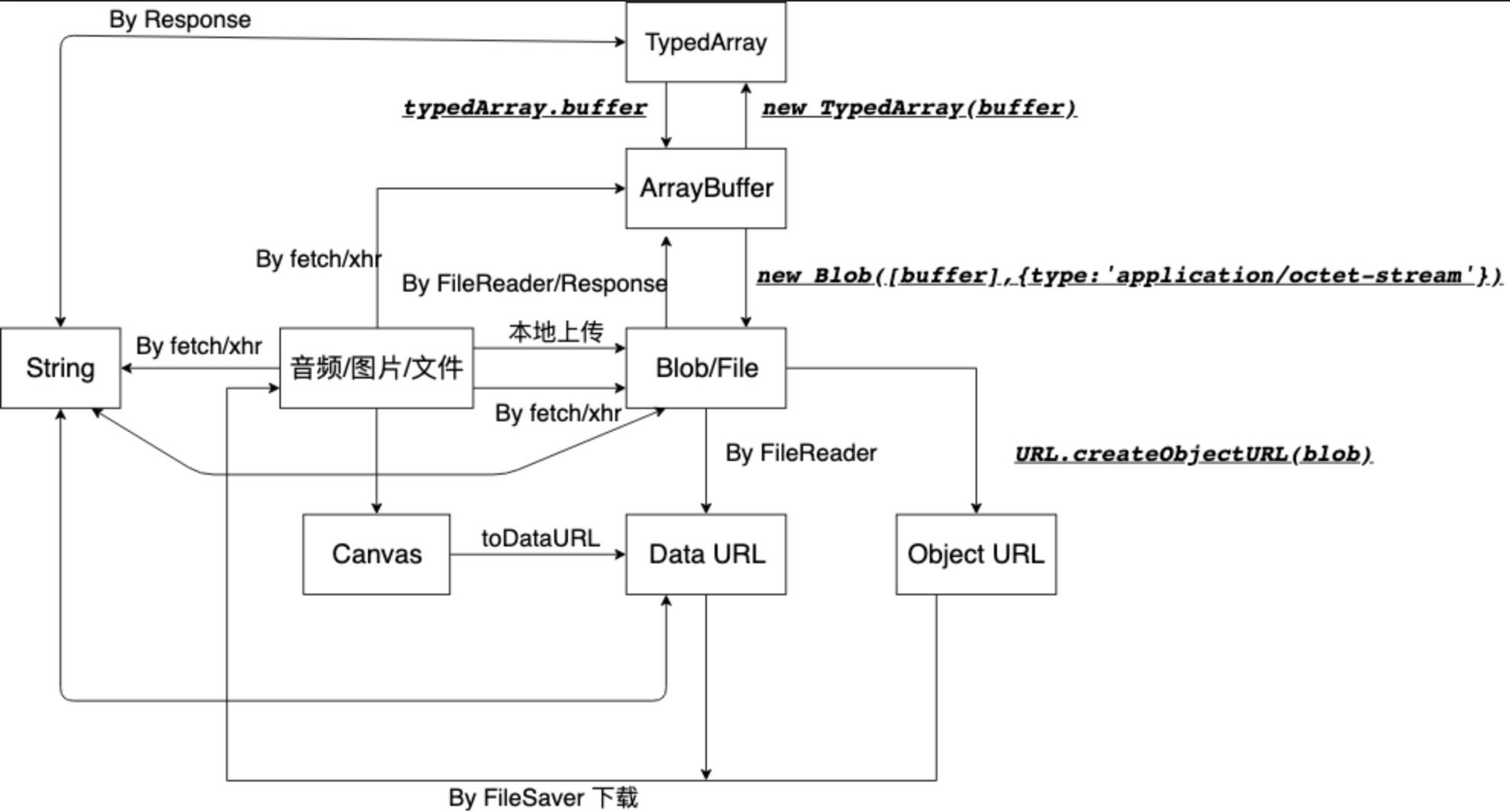
讲完了浏览器端,现在我们来讲服务器端,和浏览器不同的是,服务端上传有两个难点。
1.浏览器没有原生 formData,也不会想浏览器一样帮我们转成二进制形式。
2.服务端没有可视化的 Network 调试器。
首先我们通过最简单的示例来进行演示,然后一步一步深入。相信文档可以查看 https://github.com/request/request#multipartform-data-multipart-form-uploads
// request-error.js
const fs = require("fs");
const path = require("path");
const request = require("request");
const stream = fs.readFileSync(path.join(__dirname, "../1.png"));
request.post(
{
url: "http://localhost:7787/files",
formData: {
file: stream,
},
},
(err, res, body) => {
console.log(body);
}
);

发现报了一个错误,正像上面所说,浏览器端报错,可以用NetWork。那么服务端怎么办?这个时候我们拿出我们的利器 -- wireshark
我们打开 wireshark (如果没有或者不会的可以查看教程 https://blog.csdn.net/u013613428/article/details/53156957)
设置配置 tcp.port == 7787,这个是我们后端的端口。
运行上述文件 node request-error.js
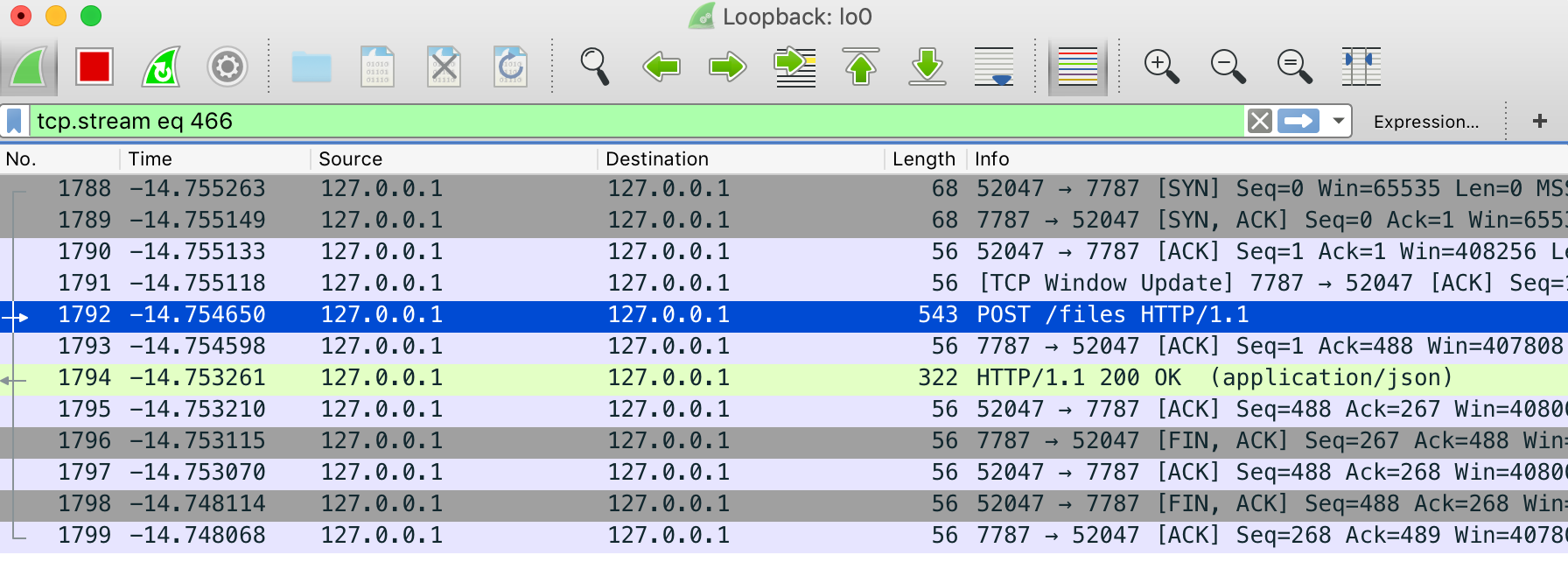
我们来找到我们发送的这条http的请求报文。中间那堆乱七八糟的就是我们的文件内容。
POST /files HTTP/1.1
host: localhost:7787
content-type: multipart/form-data; boundary=--------------------------437240798074408070374415
content-length: 305
Connection: close
----------------------------437240798074408070374415
Content-Disposition: form-data; name="file"
Content-Type: application/octet-stream
.PNG
.
...
IHDR.............%.V.....PLTE......Ll..... pHYs..........+.....
IDAT..c`.......qd.....IEND.B`.
----------------------------437240798074408070374415--
可以看到上述报文。发现我们的内容请求头 Content-Type: application/octet-stream有错误,我们上传的是图片请求头应该是image/png,并且也少了 filename="1.png"。
我们来思考一下,我们刚才用的是fs.readFileSync(path.join(__dirname, '../1.png')) 这个函数返回的是 Buffer,Buffer是什么样的呢?就是下面的形式,不会包含任何文件相关的信息,只有二进制流。
<Buffer 01 02>
所以我想到的是,需要指定文件名以及文件格式,幸好 request 也给我们提供了这个选项。
key: {
value: fs.createReadStream('/dev/urandom'),
options: {
filename: 'topsecret.jpg',
contentType: 'image/jpeg'
}
}
可以指定options,因此正确的代码应该如下(省略不重要的代码)
...
request.post({
url: 'http://localhost:7787/files',
formData: {
file: {
value: stream,
options: {
filename: '1.png'
}
},
}
});
我们通过抓包可以进行分析到,文件上传的要点还是规范,大部分的问题,都可以通过规范模板来进行排查,是否构造出了规范的样子。
我们再深入一些,来看看 request 的源码, 他是怎么实现Node端的数据传输的。
打开源码我们很容易地就可以找到关于 formData 这块相关的内容 https://github.com/request/request/blob/3.0/request.js#L21

就是利用form-data,我们先来看看 formData 的方式。
const path = require("path");
const FormData = require("form-data");
const fs = require("fs");
const http = require("http");
const form = new FormData();
form.append("file", fs.readFileSync(path.join(__dirname, "../1.png")), {
filename: "1.png",
contentType: "image/jpeg",
});
const request = http.request({
method: "post",
host: "localhost",
port: "7787",
path: "/files",
headers: form.getHeaders(),
});
form.pipe(request);
request.on("response", function(res) {
console.log(res.statusCode);
});
看完formData,可能感觉这个封装还是太高层了,于是我打算对照规范手动来构造multipart/form-data请求方式来进行讲解。我们再来回顾一下规范。
Content-type: multipart/form-data, boundary=AaB03x
--AaB03x
content-disposition: form-data; name="field1"
Joe Blow
--AaB03x
content-disposition: form-data; name="pics"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
我模拟上方,我用原生 Node 写出了一个multipart/form-data 请求的方式。
构造请求 header
构造内容 header
写入内容
写入结束分隔符
const path = require("path");
const fs = require("fs");
const http = require("http");
// 定义一个分隔符,要确保唯一性
const boundaryKey = "-------------------------461591080941622511336662";
const request = http.request({
method: "post",
host: "localhost",
port: "7787",
path: "/files",
headers: {
"Content-Type": "multipart/form-data; boundary=" + boundaryKey, // 在请求头上加上分隔符
Connection: "keep-alive",
},
});
// 写入内容头部
request.write(
`--${boundaryKey}\r\nContent-Disposition: form-data; name="file"; filename="1.png"\r\nContent-Type: image/jpeg\r\n\r\n`
);
// 写入内容
const fileStream = fs.createReadStream(path.join(__dirname, "../1.png"));
fileStream.pipe(request, { end: false });
fileStream.on("end", function() {
// 写入尾部
request.end("\r\n--" + boundaryKey + "--" + "\r\n");
});
request.on("response", function(res) {
console.log(res.statusCode);
});
至此,已经实现服务端上传文件的方式。
由于这两块就是和Buffer的转化,比较简单,我就不再重复描述了。可以作为留给大家的作业,感兴趣的可以给我这个示例代码仓库贡献这两个示例。
// base64 to buffer
const b64string = /* whatever */;
const buf = Buffer.from(b64string, 'base64');
// stream to buffer
function streamToBuffer(stream) {
return new Promise((resolve, reject) => {
const buffers = [];
stream.on("error", reject);
stream.on("data", (data) => buffers.push(data));
stream.on("end", () => resolve(Buffer.concat(buffers)));
});
}
由于服务端没有像浏览器那样 formData 的原生对象,因此服务端核心思路为构造出文件上传的格式(header,filename 等),然后写入 buffer 。然后千万别忘了用 wireshark进行验证。
这一部分是针对 Node 端进行讲解,对于那些 koa-body 等用惯了的同学,可能一样不太清楚整个过程发生了什么?可能唯一比较清楚的是 ctx.request.files ??? 如果ctx.request.files 不存在,就会懵逼了,可能也不太清楚它到底做了什么,文件流又是怎么解析的。
我还是要说到规范...请求端是按照规范来构造请求..那么我们接收端自然是按照规范来解析请求了。
const koaBody = require("koa-body");
app.use(koaBody({ multipart: true }));
我们来看看最常用的 koa-body,它的使用方式非常简单,短短几行,就能让我们享受到文件上传的简单与快乐(其他源码库一样的思路去寻找问题的本源) 可以带着一个问题去阅读,为什么用了它就能解析出文件?
寻求问题的本源,我们当然要打开 koa-body的源码,koa-body 源码很少只有 211 行,https://github.com/dlau/koa-body/blob/v4.1.1/index.js#L125 很容易地发现它其实是用了一个叫做formidable的库来解析files 的。并且把解析好的files 对象赋值到了 ctx.req.files。(所以说大家不要一味死记 ctx.request.files, 注意查看文档,因为今天用 koa-body是 ctx.request.files 明天换个库可能就是 ctx.request.body 了)
因此看完koa-body我们得出的结论是,koa-body的核心方法是formidable
那么让我们继续深入,来看看formidable做了什么,我们首先来看它的目录结构。
.
├── lib
│ ├── file.js
│ ├── incoming_form.js
│ ├── index.js
│ ├── json_parser.js
│ ├── multipart_parser.js
│ ├── octet_parser.js
│ └── querystring_parser.js
看到这个目录,我们大致可以梳理出这样的关系。
index.js
|
incoming_form.js
|
type
?
|
1.json_parser
2.multipart_parser
3.octet_parser
4.querystring_parser
由于源码分析比较枯燥。因此我只摘录比较重要的片段。由于我们是分析文件上传,所以我们只需要关心multipart_parser 这个文件。
https://github.com/node-formidable/formidable/blob/v1.2.1/lib/multipart_parser.js#L72
...
MultipartParser.prototype.write = function(buffer) {
console.log(buffer);
var self = this,
i = 0,
len = buffer.length,
prevIndex = this.index,
index = this.index,
state = this.state,
...
我们将它的 buffer 打印看看.
<Buffer 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 34 36 31 35 39 31 30 38 30 39 34 31 36 32 32 35 31 31 33 33 36 36 36 ... >
144
<Buffer 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 00 00 00 01 00 00 00 01 01 03 00 00 00 25 db 56 ca 00 00 00 06 50 4c 54 45 00 00 ff 80 80 80 4c 6c bf ... >
106
<Buffer 0d 0a 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 2d 34 36 31 35 39 31 30 38 30 39 34 31 36 32 32 35 31 31 33 33 36 ... >
我们来看wireshark 抓到的包
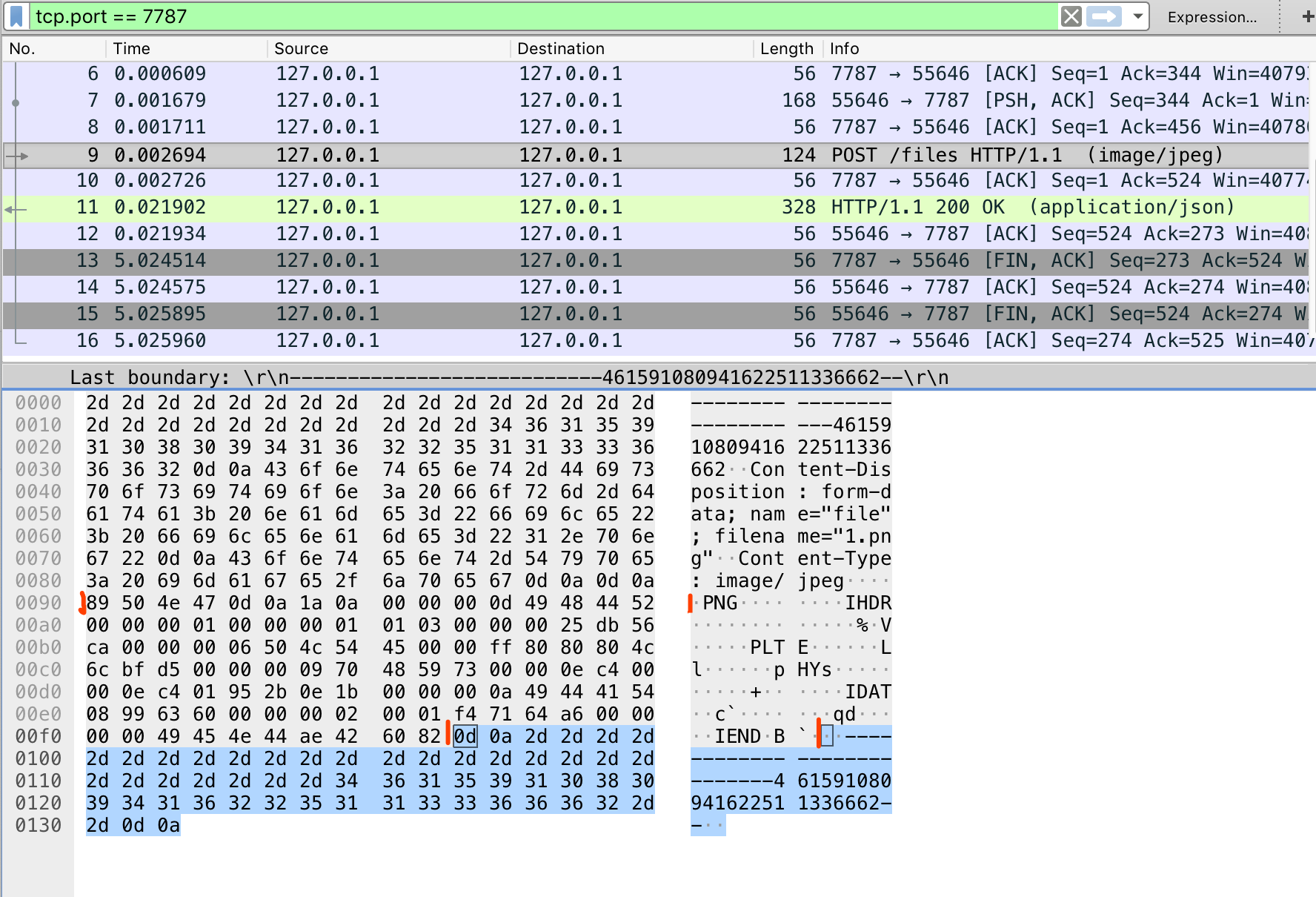
我用红色进行了分割标记,对应的就是formidable所分割的片段 ,所以说这个包主要是将大段的 buffer 进行分割,然后循环处理。
这里我还可以补充一下,可能你对以上表非常陌生。左侧是二进制流,每 1 个代表 1 个字节,1 字节=8 位,上面的 2d 其实就是 16 进制的表示形式,用二进制表示就是 0010 1101,右侧是 ascii 码用来可视化,但是 assii 分可显和非可显示。有部分是无法可视的。比如你所看到文件中有需要小点,就是不可见字符。
你可以对照,ascii 表对照表 (opens new window)来看。
我来总结一下formidable对于文件的处理流程。
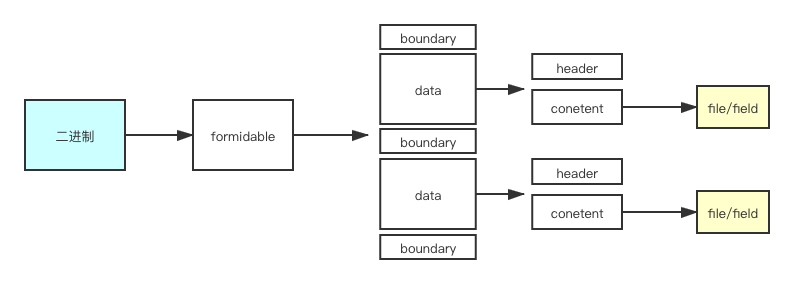
好了,我们已经知道了文件处理的流程,那么我们自己来写一个吧。
const fs = require("fs");
const http = require("http");
const querystring = require("querystring");
const server = http.createServer((req, res) => {
if (req.url === "/files" && req.method.toLowerCase() === "post") {
parseFile(req, res);
}
});
function parseFile(req, res) {
req.setEncoding("binary");
let body = "";
let fileName = "";
// 边界字符
let boundary = req.headers["content-type"]
.split("; ")[1]
.replace("boundary=", "");
req.on("data", function(chunk) {
body += chunk;
});
req.on("end", function() {
// 按照分解符切分
const list = body.split(boundary);
let contentType = "";
let fileName = "";
for (let i = 0; i < list.length; i++) {
if (list[i].includes("Content-Disposition")) {
const data = list[i].split("\r\n");
for (let j = 0; j < data.length; j++) {
// 从头部拆分出名字和类型
if (data[j].includes("Content-Disposition")) {
const info = data[j].split(":")[1].split(";");
fileName = info[info.length - 1].split("=")[1].replace(/"/g, "");
console.log(fileName);
}
if (data[j].includes("Content-Type")) {
contentType = data[j];
console.log(data[j].split(":")[1]);
}
}
}
}
// 去除前面的请求头
const start = body.toString().indexOf(contentType) + contentType.length + 4; // 有多\r\n\r\n
const startBinary = body.toString().substring(start);
const end = startBinary.indexOf("--" + boundary + "--") - 2; // 前面有多\r\n
// 去除后面的分隔符
const binary = startBinary.substring(0, end);
const bufferData = Buffer.from(binary, "binary");
fs.writeFile(fileName, bufferData, function(err) {
res.end("sucess");
});
});
}
server.listen(7787);
以上所有示例代码仓库: https://github.com/hua1995116/node-upload-demo
相信有了以上的介绍,你不再对文件上传有所惧怕, 对文件上传整个过程都会比较清晰了,还不懂。。。。找我。
再次回顾下我们的重点:
请求端出问题,浏览器端打开 network 查看格式是否正确(请求头,请求体), 如果数据不够详细,打开wireshark,对照我们的规范标准,看下格式(请求头,请求体)。
接收端出问题,情况一就是请求端缺少信息,参考上面请求端出问题的情况,情况二请求体内容错误,如果说请求体内容是请求端自己构造的,那么需要检查请求体是否是正确的二进制流(例如上面的 blob 构造的时候,我一开始少了一个[],导致内容主体错误)。
其实讲这么多就两个字: 规范 (opens new window),所有的生态都是围绕它而展开的。
https://juejin.im/post/5c9f4885f265da308868dad1
https://my.oschina.net/bing309/blog/3132260
https://segmentfault.com/a/1190000020654277