阿里云优惠活动,点击链接进行购买: 一年仅需96.9元即可以购买服务器~
腾讯云优惠活动, 点击链接进行购买一年仅需99元
腾讯云限时开团活动, 点击链接进行购买一年仅需95元
在前面一篇文章中 《模块化系列》彻底理清 AMD,CommonJS,CMD,UMD,ES6,我们可以学到了各种模块化的机制。那么接下里我们就来分析一下 webpack 的模块化机制。(主要讲 JS 部分)
提到 webpack,可以说是与我们的开发工程非常密切的工具,不管是日常开发、进行面试还是对于自我的提高,都离不开它,因为它给我们的开发带了极大的便利以及学习的价值。但是由于 webpack 是一个非常庞大的工程体系,使得我们望之却步。本文想以这种图解的形式能够将它慢慢地剥开一层一层复杂的面纱,最终露出它的真面目。以下是我列出的关于 webpack 相关的体系。

本文讲的是 打包 - CommonJS 模块,主要分为两个部分
在我们前端多样化的今天,很多工具为了满足我们日益增长的开发需求,都变得非常的庞大,例如 webpack 。在我们的印象中,它似乎集成了所有关于开发的功能,模块打包,代码降级,文件优化,代码校验等等。正是因为面对如此庞大的一个工具,所以才让我们望而却步,当然了还有一点就是,webpack 的频繁升级,周边的生态插件配套版本混乱,也加剧我们对它的恐惧。
那么我们是不是应该思考一下,webpack 的出现究竟给我们带来了什么?我们为啥需要用它?而上面所有的一些代码降级(babel 转化)、编译 SCSS 、代码规范检测都是得益于它的插件系统和 loader 机制,并不是完完全全属于它。
所以在我看来,它的功能核心是打包,而打包则是能够让模块化的规范得以在浏览器直接执行。因此我们来看看打包后所带来的功能:
如果我们不用打包的方式,我们所有的模块都是直接暴露在全局,也就是挂载在 window/global 这个对象。也许代码量少的时候还可以接受,不会有那么多的问题。特别是在代码增多,多人协作的情况下,给全局空间带来的影响是不可预估的,如果你的每一次开发都得去一遍一遍查找是否有他们使用当前的变量名。
举个例子(仅仅为例子说明,实际工程会比以下复杂许多),一开始我们的 user1 写了一下几个模块,跑起来非常的顺畅。
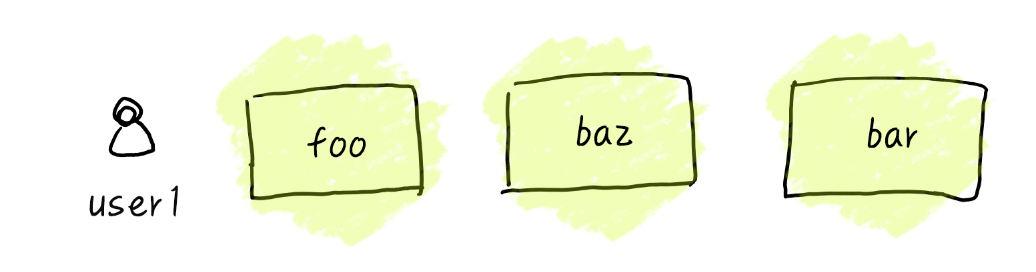
├── bar.js function bar(){}
├── baz.js function baz(){}
└── foo.js function foo(){}
但是呢,随着业务迭代,工程的复杂性增加,来了一个 user2,这个时候 user2,需要开发一个 foo 业务,里面也有一个 baz 模块,代码也很快写好了,变成了下面这个样子。
├── bar.js function bar(){}
├── baz.js function baz(){}
├── foo
│ └── baz.js function baz(){}
└── foo.js function foo(){}
但是呢这个时候,老板来找 user2 了,为什么增加了新业务后,原来的业务出错了呢?这个时候发现原来是 user2 写的新模块覆盖了 user1 的模块,从而导致了这场事故。
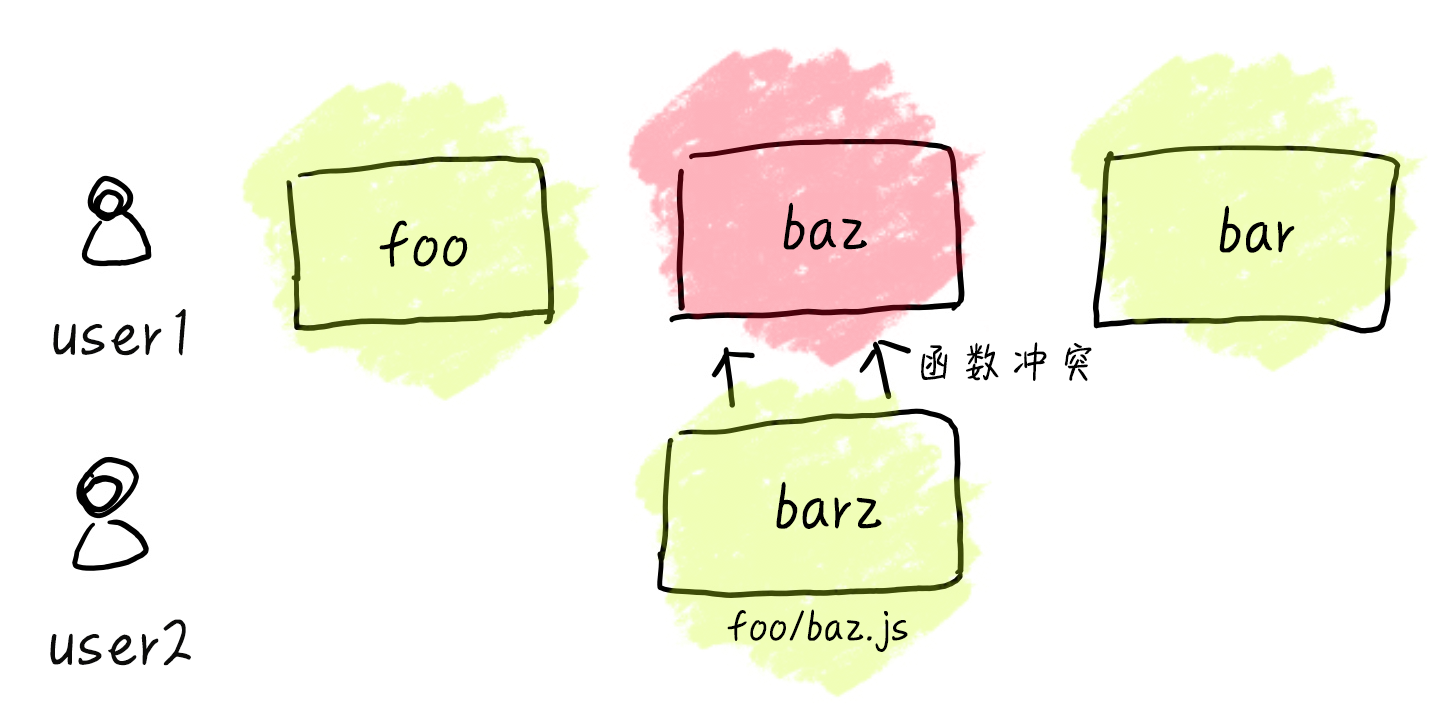
因此,当我们开发的时候将所有的模块都暴露在全局的时候,想要避免错误,一切都得非常的小心翼翼,我们很容易在不知情的偷偷覆盖我们以前定义的函数,从而酿成错误。
因此 webpack 带来的第一个核心作用就是隔离,将每个模块通过闭包的形式包裹成一个个新的模块,将其放于局部作用域,所有的函数声明都不会直接暴露在全局。
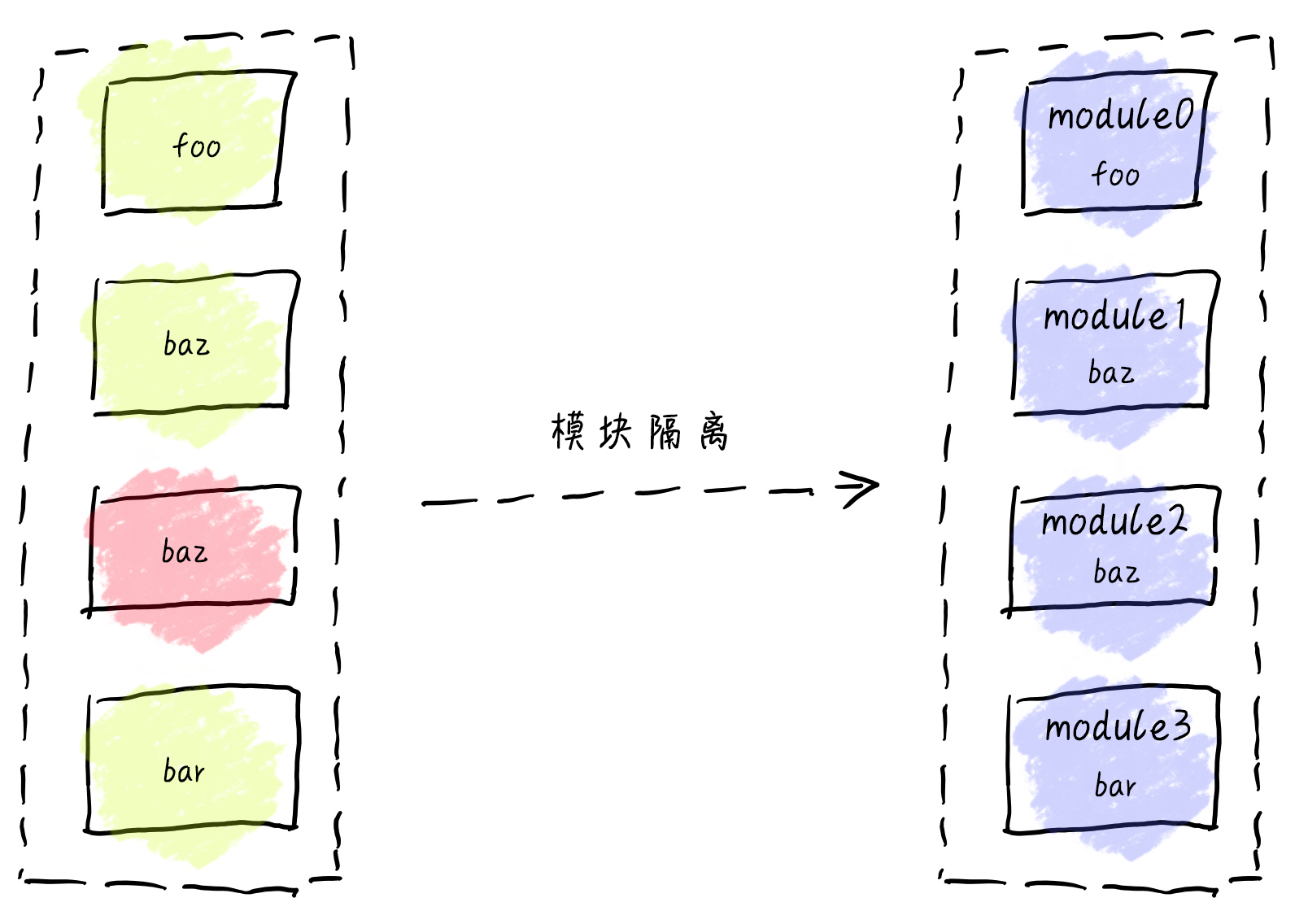
原来我们调用的 是 foo 函数,但是 webpack 会帮我们生成独一无二的模块 ID,完全不需要担心模块的冲突,现在可以愉快地书写代码啦。
baz.js;
module.exports = function baz() {};
foo / baz.js;
module.exports = function baz() {};
main.js;
var baz = require("./baz.js");
var fooBaz = require("./foo/baz.js");
baz();
fooBaz();
可能你说会之前的方式也可以通过改变函数命名的方式,但是原来的作用范围是整个工程,你得保证,当前命名在整个工程中不冲突,现在,你只需要保证的是单个文件中命名不冲突。(对于顶层依赖也是非常容易发现冲突)
还有一种重要的功能就是模块依赖加载。这种方式带来的好处是什么?我们同样先来看例子,看原来的方式会产生什么问题?
User1 现在写了 3 个模块,其中 baz 是依赖于 bar 的。

写完后 user1 进行了上线,利用了顺序来指出了依赖关系。
<script src="./bar.js"></script>
<script src="./baz.js"></script>
<script src="./foo.js"></script>
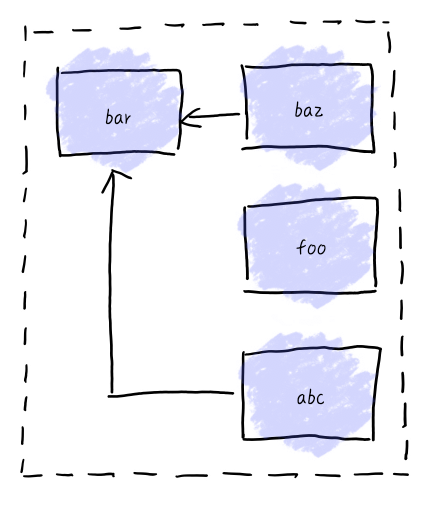
可是过了不久 user2 又接手了这个业务。user 2 发现,他开发的 abc 模块,通过依赖 bar 模块,可以进行快速地开发。可是 粗心的 user2 不太明白依赖关系。竟然将 abc 的位置随意写了一下,这就导致 运行 abc 的时候,无法找到 bar 模块。
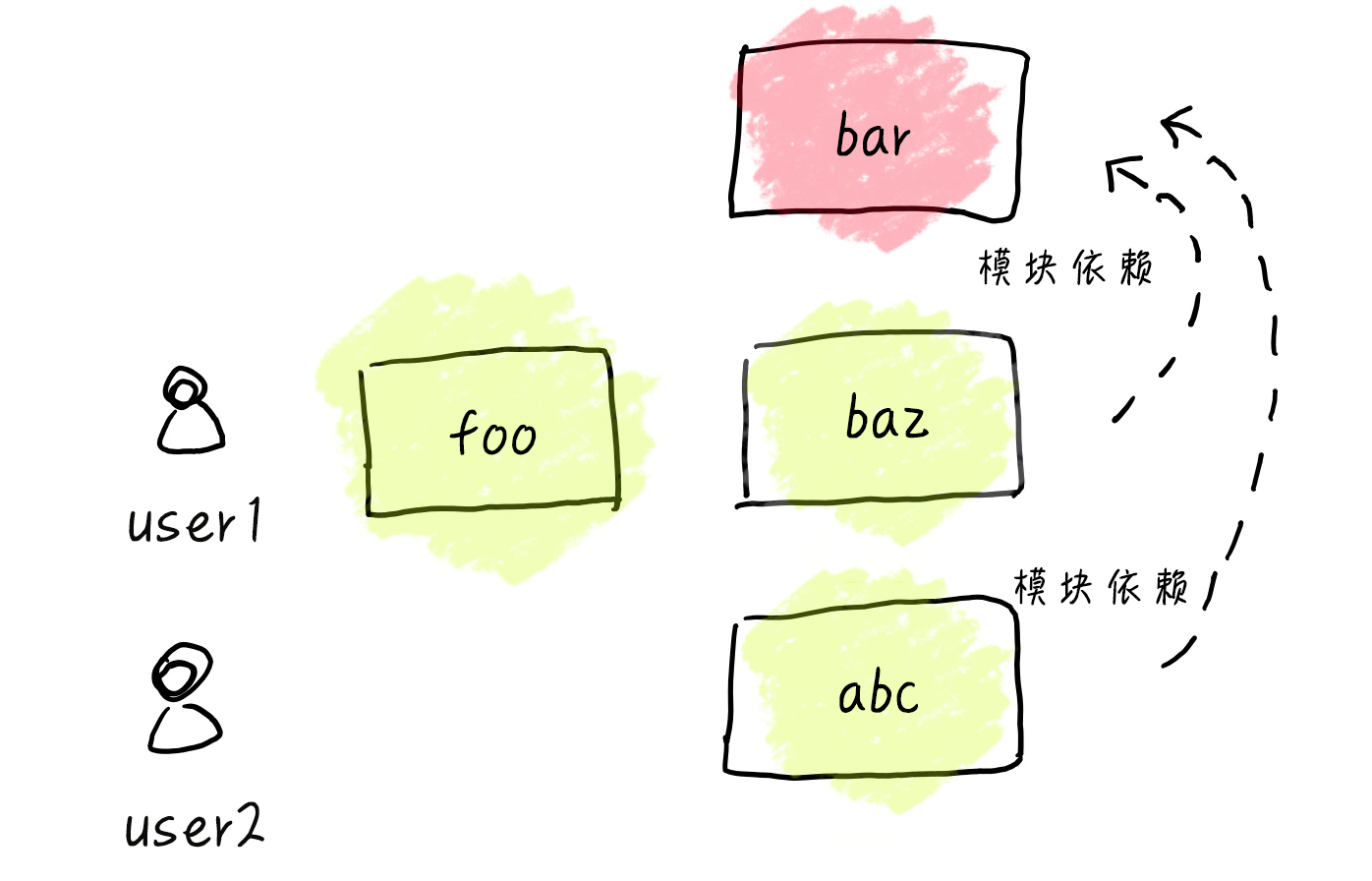
<script src="./abc.js"></script>
<script src="./bar.js"></script>
<script src="./baz.js"></script>
<script src="./foo.js"></script>
因此这里 webpack 利用 CommonJS/ ES Modules 规范进行了处理。使得各个模块之间相互引用无需考虑最终实际呈现的顺序。最终会被打包为一个 bunlde 模块,无需按照顺序手动引入。
baz.js
const bar = require('./bar.js');
module.exports = function baz (){
...
bar();
...
}
abc.js
const bar = require('./bar.js');
module.exports = function baz (){
...
bar();
...
}
<script src="./bundle.js"></script>
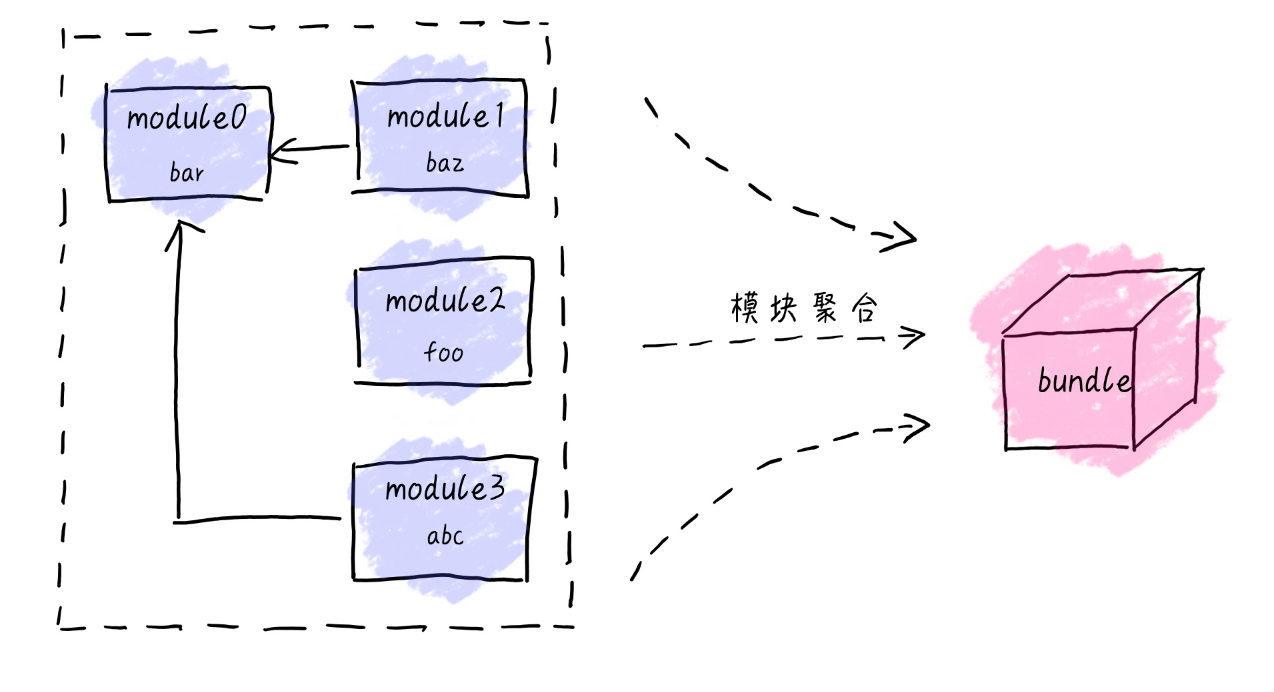
基于以上两项特性,模块的隔离以及模块的依赖聚合。我们现在可以非常清晰的知道了 webpack 所起的核心作用。
为了能够实现 webpack, 我们可以通过反推的方法,先看 webpack 打包后 bundle 是如何工作的。
源文件
// index.js
const b = require("./b");
b();
// b.js
module.exports = function() {
console.log(11);
};
build 后(去除了一些干扰代码)
(function(modules) {
var installedModules = {};
function __webpack_require__(moduleId) {
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = (installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {},
});
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
module.l = true;
return module.exports;
}
return __webpack_require__((__webpack_require__.s = 0));
})([
/* 0 */
function(module, exports, __webpack_require__) {
var b = __webpack_require__(1);
b();
},
/* 1 */
function(module, exports) {
module.exports = function() {
console.log(11);
};
},
]);
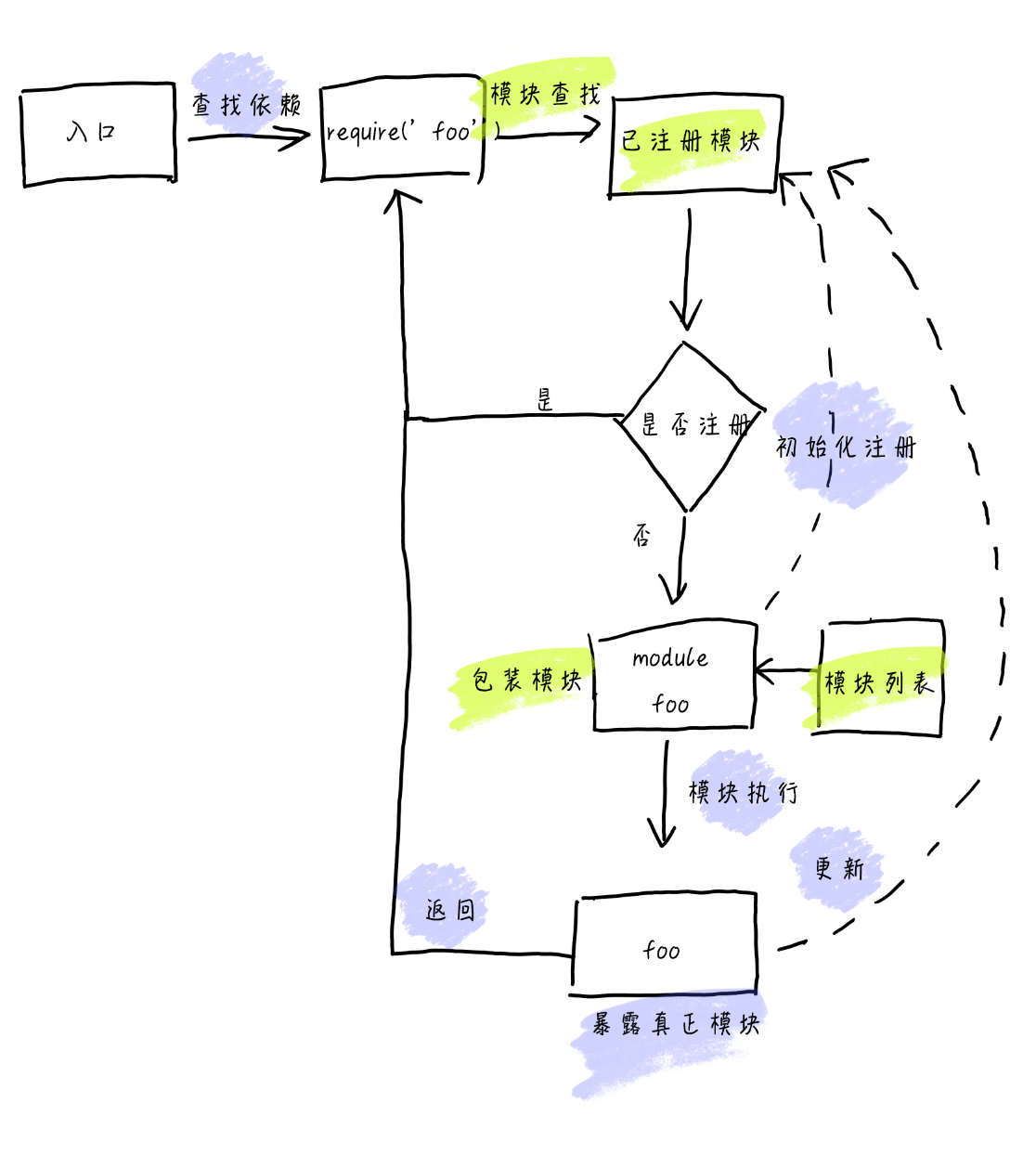
以上就是 bundle 的运作原理。通过上述的流程图我们可以看到,有四个关键点
通过 bundle 的分析,我们只需要做的就是 4 件事
首先来介绍一下模块的结构,能使我们快速有所了解, 结构比较简单,由内容和模块 id 组成。
interface GraphStruct {
context: string;
moduleId: string;
}
{
"context": `function(module, exports, require) {
const bar = require('./bar.js');
const foo = require('./foo.js');
console.log(bar());
foo();
}`,
"moduleId": "./example/index.js"
}
接下来我们以拿到一个入口文件来进行讲解,当拿到一个入口文件时,我们需要对其依赖进行分析。说简单点就是拿到 require 中的值,以便我们去寻找下一个模块。由于在这一部分不想引入额外的知识,开头也说了,一般采用的是 AST 解析的方式,来获取 require 的模块,在这里我们使用正则。
用来匹配全局的 require
const REQUIRE_REG_GLOBAL = /require\(("|')(.+)("|')\)/g;
用来匹配 require 中的内容
const REQUIRE_REG_SINGLE = /require\(("|')(.+)("|')\)/;
const context = `
const bar = require('./bar.js');
const foo = require('./foo.js');
console.log(bar());
foo();
`;
console.log(context.match(REQUIRE_REG_GLOBAL));
// ["require('./bar.js')", "require('./foo.js')"]
由于模块的遍历并不是只有单纯的一层结构,一般为树形结构,因此在这里我采用了深度遍历。主要通过正则去匹配出require 中的依赖项,然后不断递归去获取模块,最后将通过深度遍历到的模块以数组形式存储。(不理解深度遍历,可以理解为递归获取模块)
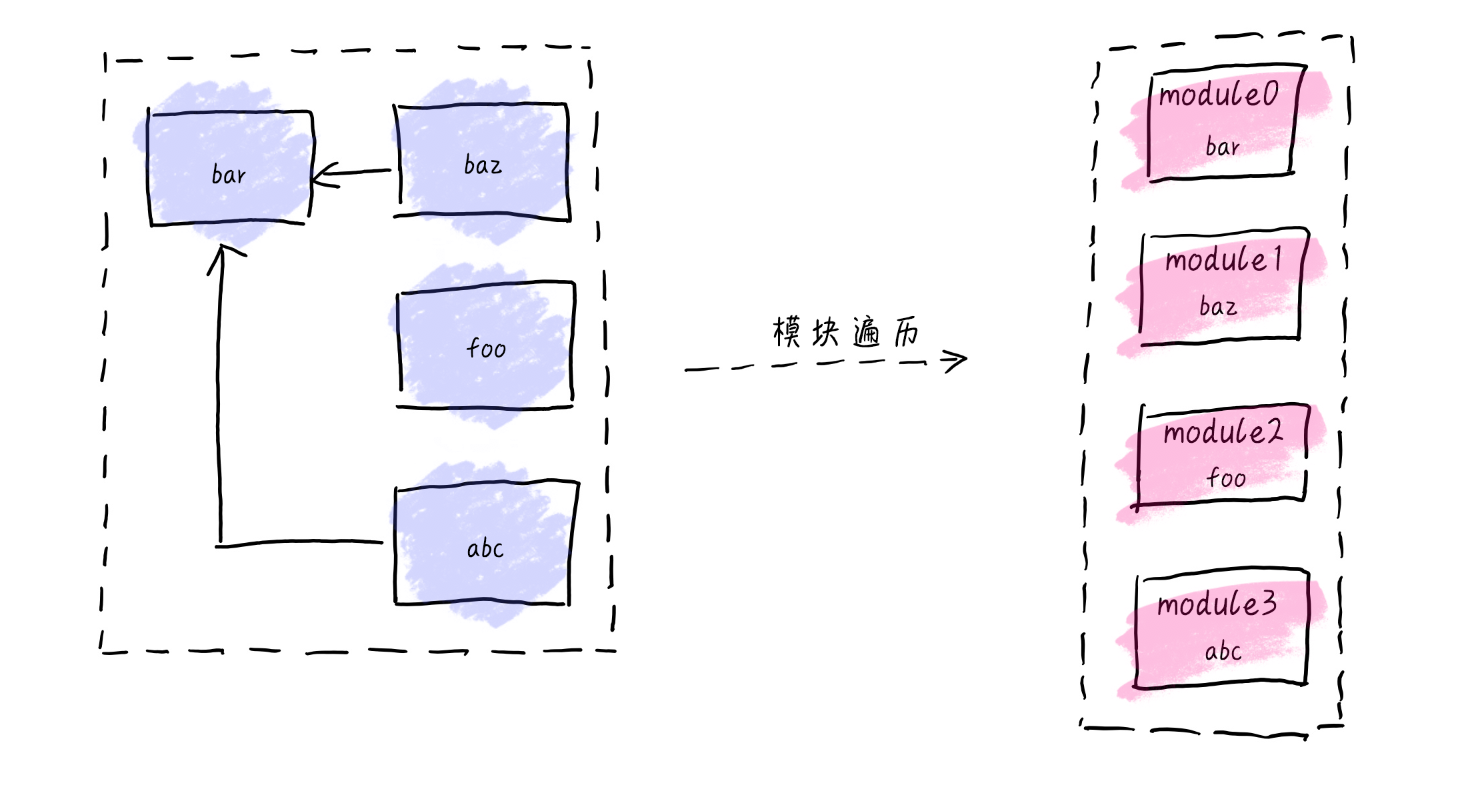
以下是代码实现
...
private entryPath: string
private graph: GraphStruct[]
...
createGraph(rootPath: string, relativePath: string) {
// 通过获取文件内容
const context = fs.readFileSync(rootPath, 'utf-8');
// 匹配出依赖关系
const childrens = context.match(REQUIRE_REG_GLOBAL);
// 将当前的模块存储下来
this.graph.push({
context,
moduleId: relativePath,
})
const dirname = path.dirname(rootPath);
if (childrens) {
// 如有有依赖,就进行递归
childrens.forEach(child => {
const childPath = child.match(REQUIRE_REG_SINGLE)[2];
this.createGraph(path.join(dirname, childPath), childPath);
});
}
}
为了能够使得模块隔离,我们在外部封装一层函数, 然后传入对应的模拟 require 和 module使得模块能进行正常的注册以及导入 。
function (module, exports, require){
...
},
这一步比较简单,只要按照我们分析的流程图提供已注册模块变量、模块列表变量、导入函数。
/* modules = {
"./example/index.js": function (module, exports, require) {
const a = require("./a.js");
const b = require("./b.js");
console.log(a());
b();
},
...
};*/
bundle(graph: GraphStruct[]) {
let modules = '';
graph.forEach(module => {
modules += `"${module.moduleId}":function (module, exports, require){
${module.context}
},`;
});
const bundleOutput = `
(function(modules) {
var installedModules = {};
// 导入函数
function require(moduleId) {
// 检查是否已经注册该模块
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 没有注册则从模块列表获取模块进行注册
var module = (installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {},
});
// 执行包装函数,执行后更新模块的内容
modules[moduleId].call(
module.exports,
module,
module.exports,
require
);
// 设置标记已经注册
module.l = true;
// 返回实际模块
return module.exports;
}
require("${graph[0].moduleId}");
})({${modules}})
`;
return bundleOutput;
}
最后将生成的 bundle 持久写入到磁盘就大功告成。
fs.writeFileSync("bundle.js", this.bundle(this.graph));
完整代码 100 行 代码不到,详情可以查看以下完整示例。
github 地址: https://github.com/hua1995116/tiny-webpack
以上仅代表个人的理解,希望让你对 webpack 的理解有所帮助, 如有讲的不好的请多指出。
欢迎关注公众号 「秋风的笔记」,主要记录日常中觉得有意思的工具以及分享开发实践,保持深度和专注度。回复 webpack 获取概览图 xmind 原图。

Q: 为什么打算写这篇文章?
R: 其实主要是为了画图,纯粹比较新奇。
Q: 还会有下一篇吗?
R: 有的,下一篇暂定为 ES module 和 code splitting 相关。